Data Abstraction
Data Abstraction is an extremely common term thrown around when talking about programming methodologies. But what does it really mean?
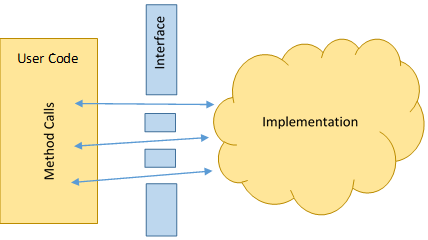
Essentially, an abstraction is a construct that separates the implementation of some thing from its use cases. It "encapsulates" some generalized implementation within a consistent interface. Remember the first lesson on C++—data abstraction? Variables are an example of an abstraction. They abstract the process of reading and writing values to a simple interface of assignment and arithmetic.
In practical programming, data abstraction involves separating the interface (or the API) of some system from its implementation. In C++, this is usually realized through the use of classes and their associated access patterns. For example, one might create a "list" abstraction, where the interface includes methods to store and retrieve ordered values. The underlying implementation does not need to be known to be able to use this "list."
However, this is by no means the only type of data abstraction. Functions, data structures, objects, APIs, languages—these are all abstractions. What they have in common is simply that they provide a usable interface to a more "abstract" (or general) layer, whether that be more specific code, low-level hardware operations, or even another language.
But why is data abstraction useful? The biggest benefit is that it allows the "larger" program to use the abstraction consistently and without modification, even if the implementation underneath the abstraction changes dramatically. If the underlying structure of the "list" was changed from an array to a linked list, the code that uses the "list" interface should not have to be updated.
Data Hiding
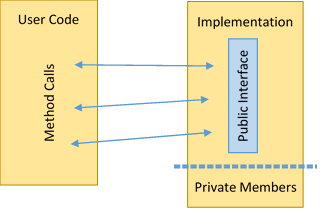
Abstraction is closely related to the concept of data hiding. Data hiding is simply the process of actually hiding the implementation of an abstraction in such a way that the user code cannot touch it. While it's debatable if data hiding should always be upheld, it provides a useful level of security, as it assures that the abstracted implementation operates in its own sphere, not having to worry about other code sneaking in and changing things.
In C++, this typically refers to the use of private and protected members, as well as interfaces. We've covered class access modifiers before, so we won't go over those again now. However, what is an interface? Some languages, such as Java, allow you to define "interface" classes that fully define, well, an interface. This is also known as an "implementation contract." If a class wants to implement the interface, it inherits the required interface and can be used consistently by the interface specification. In C++, interfaces may be defined by creating a base class with only pure virtual methods. However, using polymorphism always incurs some performance overhead, so C++ interfaces are rarely used in practice. Instead, "hidden" data members are simply marked as "private" or "protected."
APIs
An API, or Application Programming Interface, is a term for one of these interfaces to an abstraction. APIs can be big or small or anywhere in between. Hitherto, I've referred to relatively small APIs—for example, a single class. However, APIs for larger abstractions—say, a graphics library—may span many different functions, classes, interfaces, enumerations, even languages.
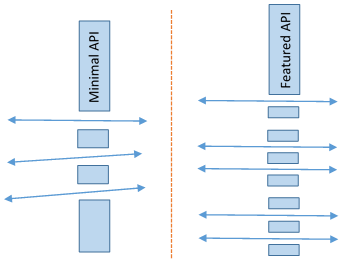
APIs tend to fall into two main categories of design: minimal and featured. Minimal APIs only include enough functionality as is necessary for use in a larger project. Minimal APIs tend to develop when one creates an abstraction within a project. An example of this might be a data structure for a specific use.
Featured APIs, on the other hand, seek to provide functionality suited for all conceivable use cases within its domain, even if that means much of it will never be used within a specific project. This type of design is useful in creating APIs to be used across many projects, or to distribute to many people. If large enough, big APIs tend to introduce their own style of use, syntax, and thought—a domain-specific language. Featured APIs include libraries like SDL, OpenGL, DirectX, Boost, and many others.
Modularity & Coupling
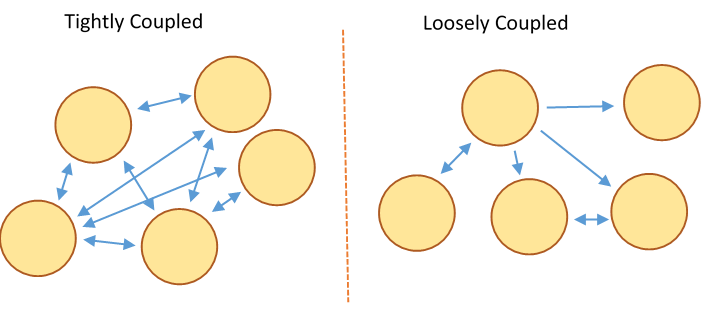
Another objective of data abstraction is modularity. As you might guess, modularity is a measure of how easily a unit can be re-purposed, replaced, moved, or otherwise changed. The ideal situation of modularity allows you to pull out any component of a program and use it elsewhere—and add anther implementation of that component seamlessly back into your main program.
This is closely related to coupling, a measure of how much a component depends on others. If some abstraction relies on several other components of the program to function property, it is seen as highly coupled. Coupling reduces modularity: it pretty clearly makes it much harder to have and to separate modules from the whole. However, some degree of coupling is always required—the components of a program must work together somehow. Limiting coupling helps reduce overall program complexity and makes it much easier to change individual parts. In C++, this is most often achieved by limiting systems or classes to one specific domain of tasks and reducing the amount they must interface with other systems. Separate modules can then be orchestrated by a "controller" module.